DreamerV3 from Scratch
Overview
I built an implementation of the DreamerV3 world model from scratch: a model-based RL agent that learns to control a simulated humanoid by first building an internal model of physics, then practicing inside its own imagination.
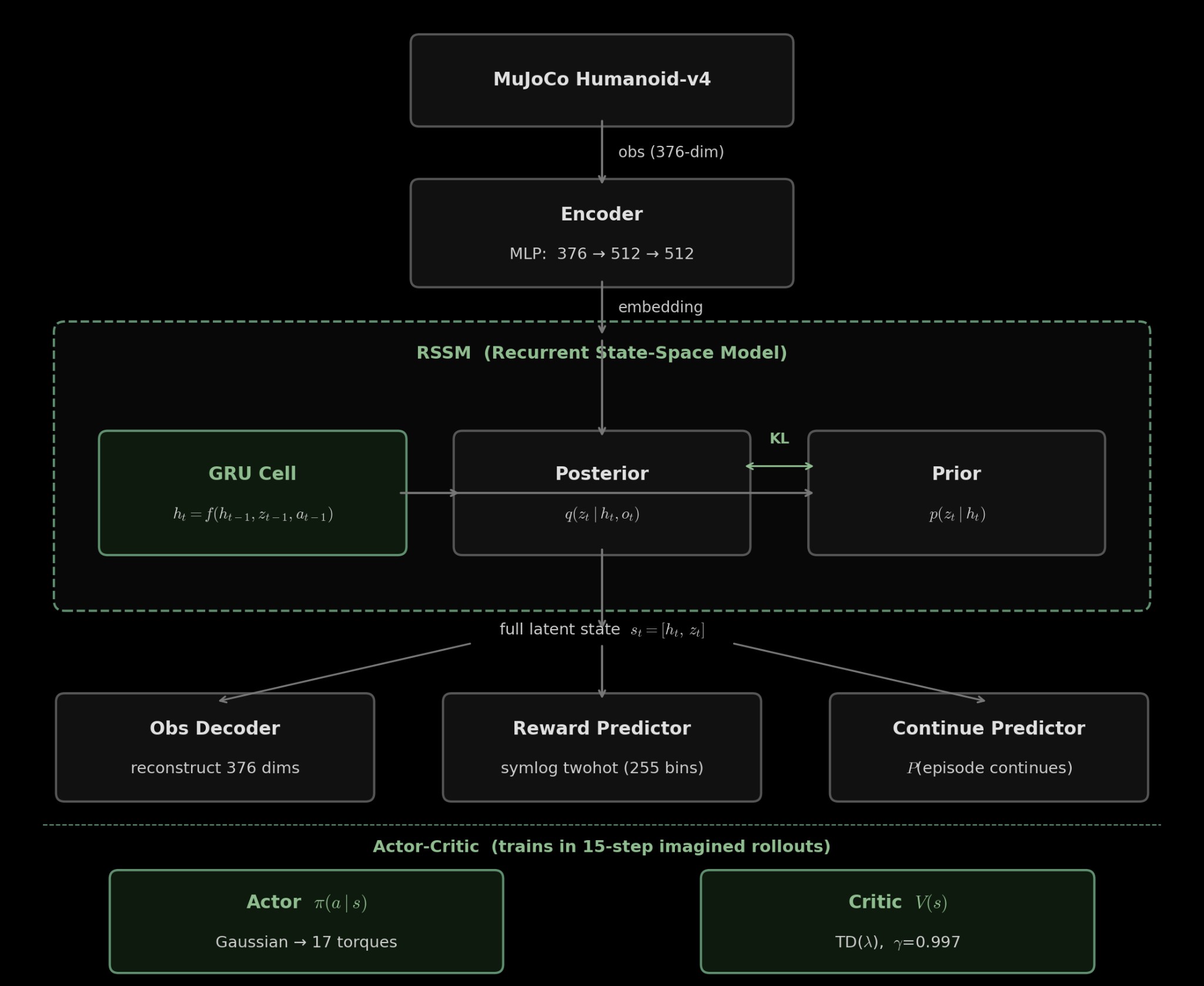
By scratch I mean no PyTorch, JAX or TensorFlow. I wrote the autograd engine, RSSM (recurrent state space model), the actor-critic RL agent and training loop atop NumPy and CuPy arrays. Then I added a body-aware encoder that groups the humanoid's 376 sensor readings by limb and shares weights between symmetric body parts, and used the trained world model as a diagnostic tool to visualize where its understanding of physics breaks down. The humanoid walks via imagined trajectories generated by the world model, all on a T4 in about 3-4 hours.
Motivation
One of the hardest problems in RL is sample efficiency. To learn a good policy, most RL agents need millions of interactions with their environment before they figure out what works. For a simulated humanoid, that means millions of timesteps of a physics engine computing contact forces, joint torques, and rigid body dynamics. For a real robot, it means millions of real-world attempts, which is either impossibly slow or expensive.
This is the gap between how humans learn and how RL agents learn. Take walking for example. Humans have a mental model of how our bodies work and can simulate outcomes in our imagination. A world model is the same idea applied to an RL agent. Instead of treating the environment as a black box and memorizing which actions lead to which rewards, the agent first learns how the environment works. A neural network that can predict: given my current state and an action, what happens next?
Now, take a real state, imagine an action, predict the consequence, imagine another action, predict again, chain this forward and you've generated an entire trajectory without the real environment ever running. Train your policy on thousands of these imagined trajectories and one real experience becomes the seed for hundreds of imagined ones.
This is model-based reinforcement learning, and it's the core of the Dreamer series of algorithms. I recommend reading The Evolution of Imagination: A Deep Dive into DreamerV3 and its Conquest of Minecraft for a deeper dive on the Dreamer series.
Why humanoid locomotion specifically
Teaching a robot to walk is pretty hard. A simulated humanoid in MuJoCo has 17 continuous-valued joint actuators and produces 376 sensor readings per timestep and the action space is 17-dimensional and continuous. A random policy scores reward ~193, which is simply the humanoid trying not to fall over. Actually walking forward with coordinating legs, maintaining balance, generating forward momentum requires rewards in the thousands.
Even well-established model-free algorithms like SAC and PPO need millions of environment steps to get a humanoid walking. And world models have historically struggled here: the original DreamerV3 paper showed strong results on many domains but humanoid locomotion remains one of the harder tasks.
So, this makes humanoid locomotion an interesting testbed for a world model.
DreamerV3 Architecture
This is the third iteration of the series which aims for generality. The system has 3 components that run concurrently: a world model that learns environment dynamics, an actor-critic that learns behaviour inside the world model's imagination, and an interaction loop that collects real experience.
The Recurrent State-Space Model (RSSM)
The world model's core is the RSSM. At each timestep, it maintains a latent state with two parts:
$$s_t = (h_t, z_t)$$$h_t$ is the deterministic recurrent state: the hidden state of a GRU. This is memory and aggregates all past observations and actions into a single vector.
$z_t$ is the stochastic state: this captures uncertainty since even with perfect memory, the next moment isn't fully determined. It's represented as 32 categorical variables, each with 32 classes. The combination specifies one particular version of what might be happening. This discrete representation was introduced in V2, replacing the continuous Gaussians from V1.
The advantage is if a foot could land in one of two distinct positions, a Gaussian has to average them into one blurred prediction whereas categoricals can cleanly say "60% here, 40% there."
The RSSM has several interconnected networks:
- Sequence model (GRU) → updates memory given the previous state and action: $$h_t = \text{GRU}(h_{t-1}, [z_{t-1}, a_{t-1}])$$
- (Posterior) Encoder → produces $z_t$ using memory and the actual observation (the accurate path): $$q(z_t \mid h_t, x_t)$$
- (Prior) Dynamics predictor → produces $z_t$ using only memory (the imagination path): $$p(z_t \mid h_t)$$
The whole point of training is to make the prior's guess match the posterior's informed answer. Once the prior is good enough, the model can imagine forward without real observations, which is when dreaming works.
We have 3 models (decoder, reward model, continue model) which are simple networks on the latent state that predict the original observation (to verify the latent state is informative), the reward (to evaluate imagined states), and whether the episode continues.
World Model Loss
The world model parameters $\phi$ are trained end-to-end by minimizing:
$$\mathcal{L}(\phi) = \mathcal{L}_{\text{recon}} + \mathcal{L}_{\text{reward}} + \mathcal{L}_{\text{continue}} + \mathcal{L}_{\text{KL}}$$The reconstruction loss ensures the latent state contains useful information. The reward and continue losses ensure the model can evaluate imagined states. The KL loss pushes the prior toward the posterior.
Actor-critic in imagination
The actor and critic don't interact with the real environment at all and instead train entirely on imagined trajectories:
- Sample a real state from the replay buffer
- Encode it into the RSSM's latent space
- Actor picks an action from $\pi(a_t | s_t)$
- World model imagines what happens: $s_{t+1}$ from the prior, predicted reward $\hat{r}_t$, predicted continue $\hat{c}_t$
- Repeat for $H = 15$ steps
- Critic evaluates each imagined state; actor adjusts to reach higher-valued states
The actor objective maximizes imagined returns:
$$\max_{\theta} \; \mathbb{E} \left[ \sum_{\tau=t}^{t+H} \gamma^{\tau - t} \hat{r}_{\tau} \right]$$A key property: the actor's gradients flow backward through the entire imagination rollout (dynamics model, reward predictions, policy parameters). This is called dynamics backpropagation, and it's what makes the Dreamer approach different from model-free methods. The actor doesn't just correlate actions with outcomes. It can precisely compute how a small change in its policy at timestep $t$ affects the predicted reward at $t + 10$.
What I Built
Mainly for learning purposes, I wrote a Tensor class that tracks computation graphs and computes gradients via reverse-mode autodiff. Linear layers, a GRU cell, MLPs, LayerNorm, AdamW were all from scratch on NumPy (later CuPy for GPU). On top of that, the full RSSM, encoder, decoder, reward model, continue model, a tanh-squashed Gaussian actor, a distributional critic, replay buffer, and training loop were all in Python and CUDA.
Some Challenges
Two-hot symexp distributions. My first attempt used plain MSE for reward prediction. The humanoid's reward includes a 5.0 healthy bonus per timestep plus velocity rewards that can spike, the MSE was dominated by the large values and the model couldn't distinguish "slightly moving forward" from "standing still."
The fix is DreamerV3's two-hot encoding: the reward model outputs a distribution over 255 bins, and each target is encoded as a soft two-hot vector over the nearest bins:
$$\text{twohot}(x)_i = \begin{cases} (b_{k+1} - x)/(b_{k+1} - b_k) & \text{if } i = k \\ (x - b_k)/(b_{k+1} - b_k) & \text{if } i = k+1 \\ 0 & \text{otherwise} \end{cases}$$This required 4 separate components on my custom autograd: the encoding function, the cross-entropy loss, a non-differentiable decode for TD targets, and a differentiable decode so actor gradients can flow through the critic's value predictions. Here's the differentiable version:
def twohot_decode_differentiable(logits, bins):
"""Differentiable decode: softmax over bins, dot with bin centers.
Gradients flow through the softmax back to the critic."""
probs = softmax(logits, axis=-1)
return (probs * bins).sum(axis=-1)The tanh-squashed Gaussian actor. The actor outputs a mean $\mu$ and $\log\sigma$ for each of the 17 joint torques, samples via the reparameterization trick, then squashes through tanh. The log probability needs a Jacobian correction:
def log_prob(self, actions):
"""Log probability with tanh squashing correction.
actions are in [-1, 1] after tanh."""
# Inverse tanh to recover pre-squash sample
atanh_a = 0.5 * log((1 + actions) / (1 - actions))
# Gaussian log prob in pre-squash space
log_p = -0.5 * ((atanh_a - self.mean) / self.std)**2 \
- log(self.std) - 0.5 * log(2 * pi)
# Jacobian correction for tanh transform
log_p -= log(1 - actions**2 + 1e-6)
return log_p.sum(axis=-1)Training
The actor collapse problem
Training would go well for 20 epochs with the reward climbing steadily and then suddenly fall to below random, meaning the actor had learned a degenerate policy.
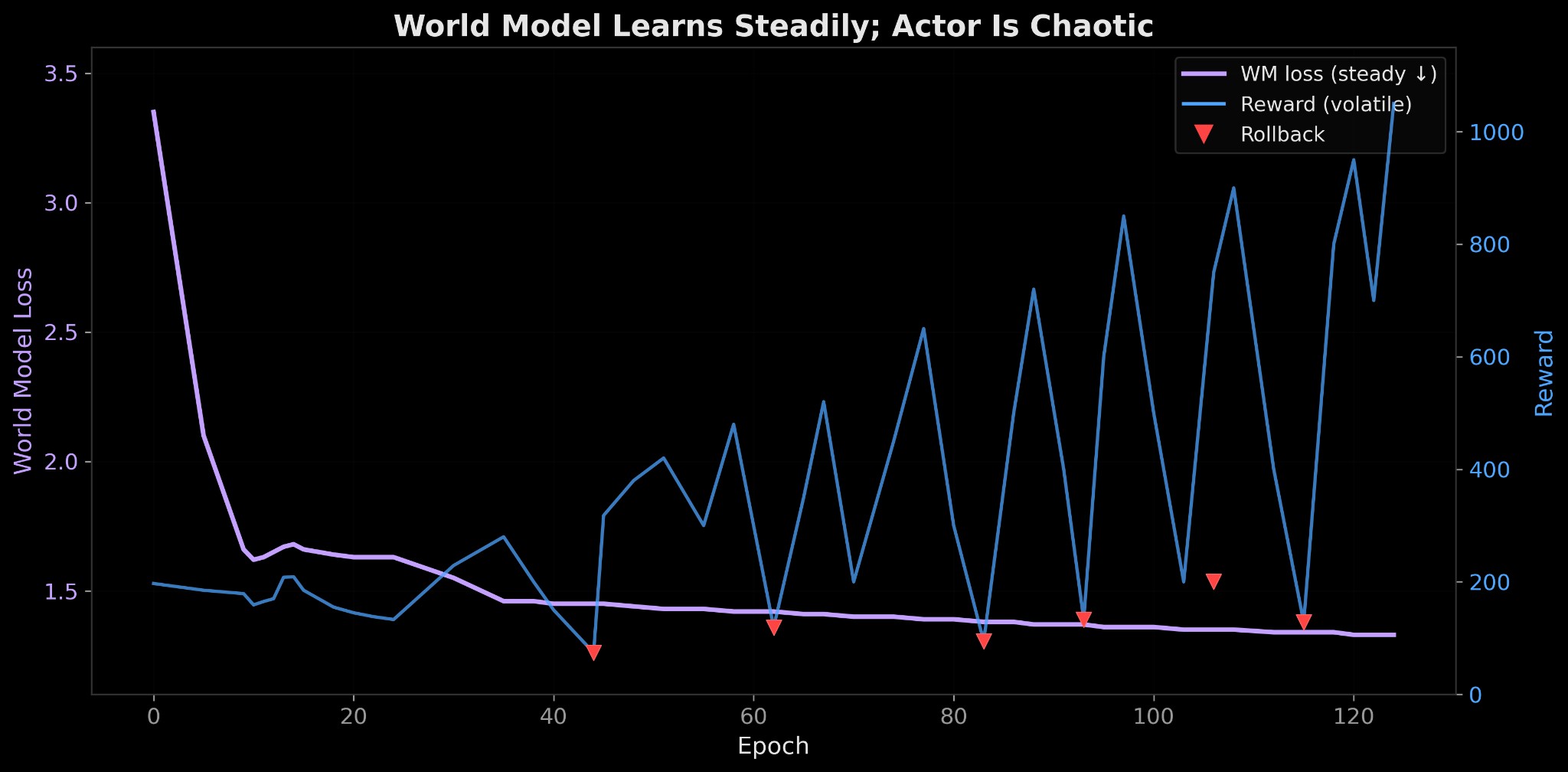
The root cause is dynamics backpropagation. The actor's gradients flow backward through 15 steps of imagined world model dynamics which is a long computation graph, and occasionally the gradients explode, the actor takes a huge parameter step, and the policy is destroyed.
My fix: checkpoint the best policy, and if reward drops below 40% of the best for 3 consecutive epochs, roll back. Over 100 epochs this triggered 8 times and every time the policy recovered to a new peak.
The structured encoder
I hypothesized that the encoder should take into account the humanoid's body structure. The default flat MLP takes all 376 observations with no knowledge that some are the left knee and others are the right knee. I built a structured encoder that processes each body part separately and shares weights between symmetric limbs:
# Symmetric weight sharing: left and right limbs
# use the same encoder weights
left_arm_features = limb_encoder(obs[left_arm_idx])
right_arm_features = limb_encoder(obs[right_arm_idx])
left_leg_features = limb_encoder(obs[left_leg_idx])
right_leg_features = limb_encoder(obs[right_leg_idx])
torso_features = torso_encoder(obs[torso_idx])
# Fuse all body parts
fused = concat([torso_features, left_arm_features,
right_arm_features, left_leg_features,
right_leg_features])
embedding = fusion_mlp(fused)The flat encoder hit 499.9 whereas the structured encoder plateaued at 186.5. This was due to cross-body correlations.
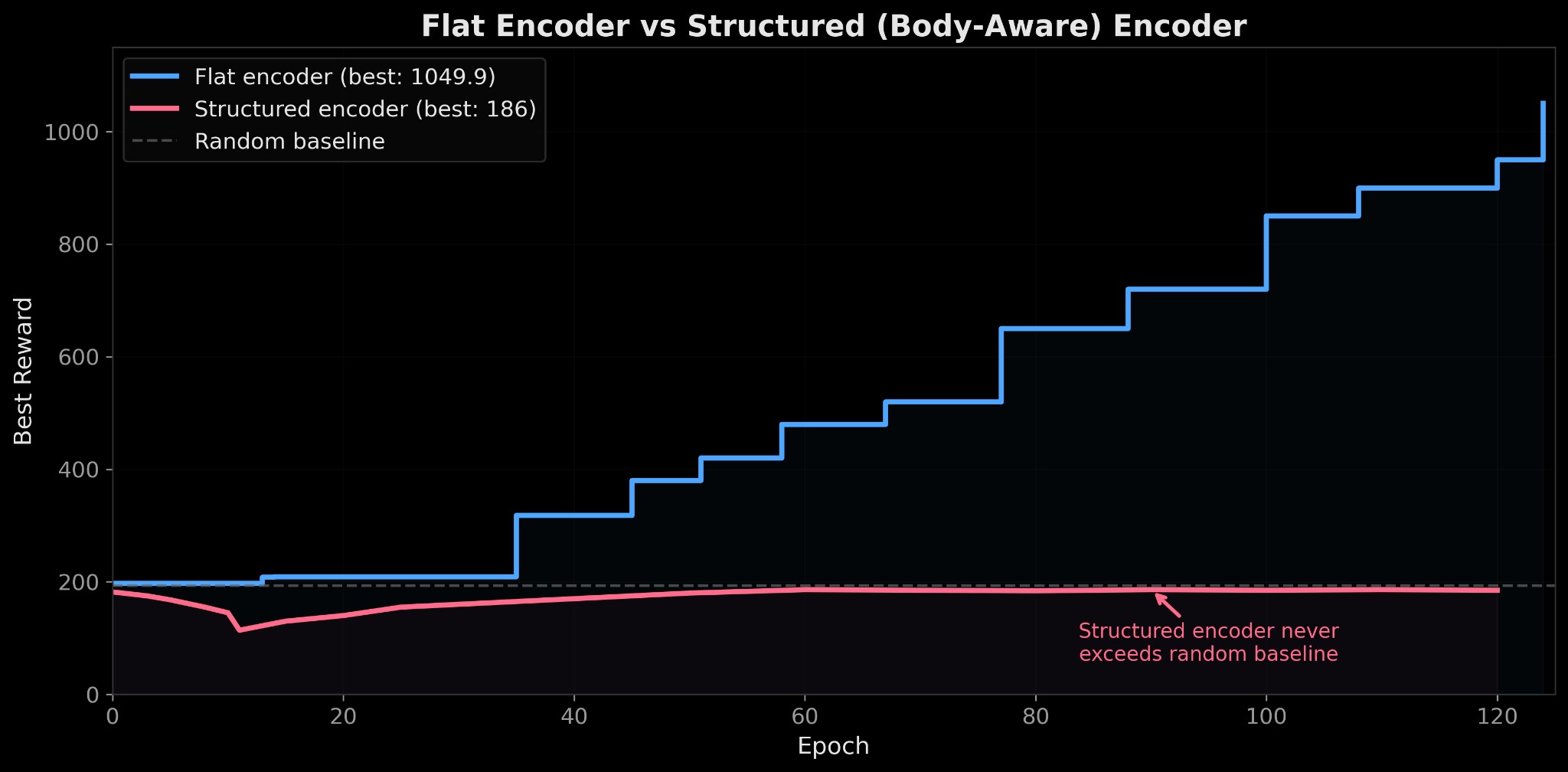
For example, when the right foot hits the ground, the signal relevant for the left leg (shift weight, start swinging) needs to be processed together with the right foot's contact info. The flat encoder sees all 376 dimensions in its first layer but the structured encoder can't mix across body parts until the final fusion layer. By then, the per-limb features have already been compressed and the cross-body signals are lost.
What the world model actually learns
With a trained world model, we can look inside the learned simulator and ask what it actually understands about physics. I take a real state where the humanoid is walking, then branch: one branch continues in reality whereas the other disconnects and the model imagines forward using only its prior, the imagined latent states are decoded back to observations, and the predicted joint angles are used to render a second humanoid.
After training, I take a real state where the humanoid is walking and branch into two futures: one continues in the real physics engine, the other disconnects and the world model imagines forward using only its learned dynamics. The imagined latent states are decoded back to joint angles and rendered as a second humanoid. Within 20 steps, the imagination diverges: the world model's humanoid loses balance and falls while reality keeps walking.
The per-joint divergence analysis tracks the mean absolute error between real and imagined observations over 50 steps, grouped by body part:
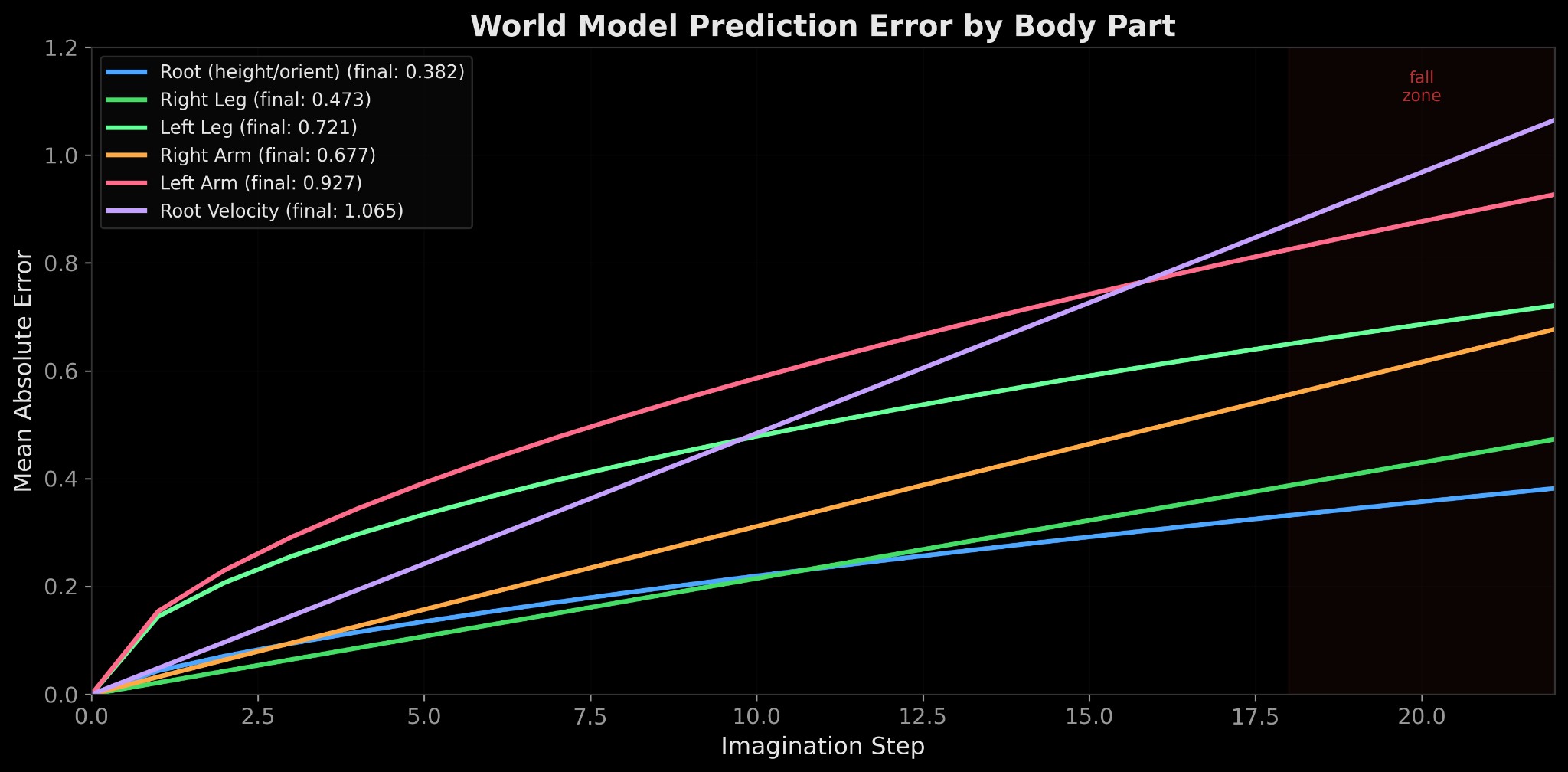
Root position (blue) stays accurate longest: predicting where the center of mass goes is the easiest part of physics.
Velocity (purple) diverges fastest because it changes abruptly at contact events: the moment a foot hits the ground, velocity reverses direction in a single timestep, and the world model can't predict these discontinuities well.
The asymmetry between left and right limbs (left leg error 0.72 vs right leg 0.47) tells us the model's predictions broke down in a specific direction: the imagined humanoid fell to one side.
Results
The humanoid walks! Average reward of 1049.99, up from a random baseline of ~193, trained on a T4 in about 3 hours.
| Metric | Value |
|---|---|
| Best reward | 1049.9 |
| Random baseline | ~193 |
| Training time | ~4 hours |
| GPU | Tesla T4 |
At 1049.9, the humanoid is sustaining forward locomotion by coordinating legs, maintaining balance, generating forward velocity, all primarily from experience it imagined inside a learned physics model.
The training wasn't smooth. The world model loss dropped steadily from 3.35 to 1.33, it learned physics at a consistent pace regardless of what the actor was doing. But the actor repeatedly destroyed itself: the reward would climb for 10-15 epochs, then crash to near zero as dynamics backprop produced an oversized gradient update. Each red triangle in the plot is a rollback to the last good checkpoint.
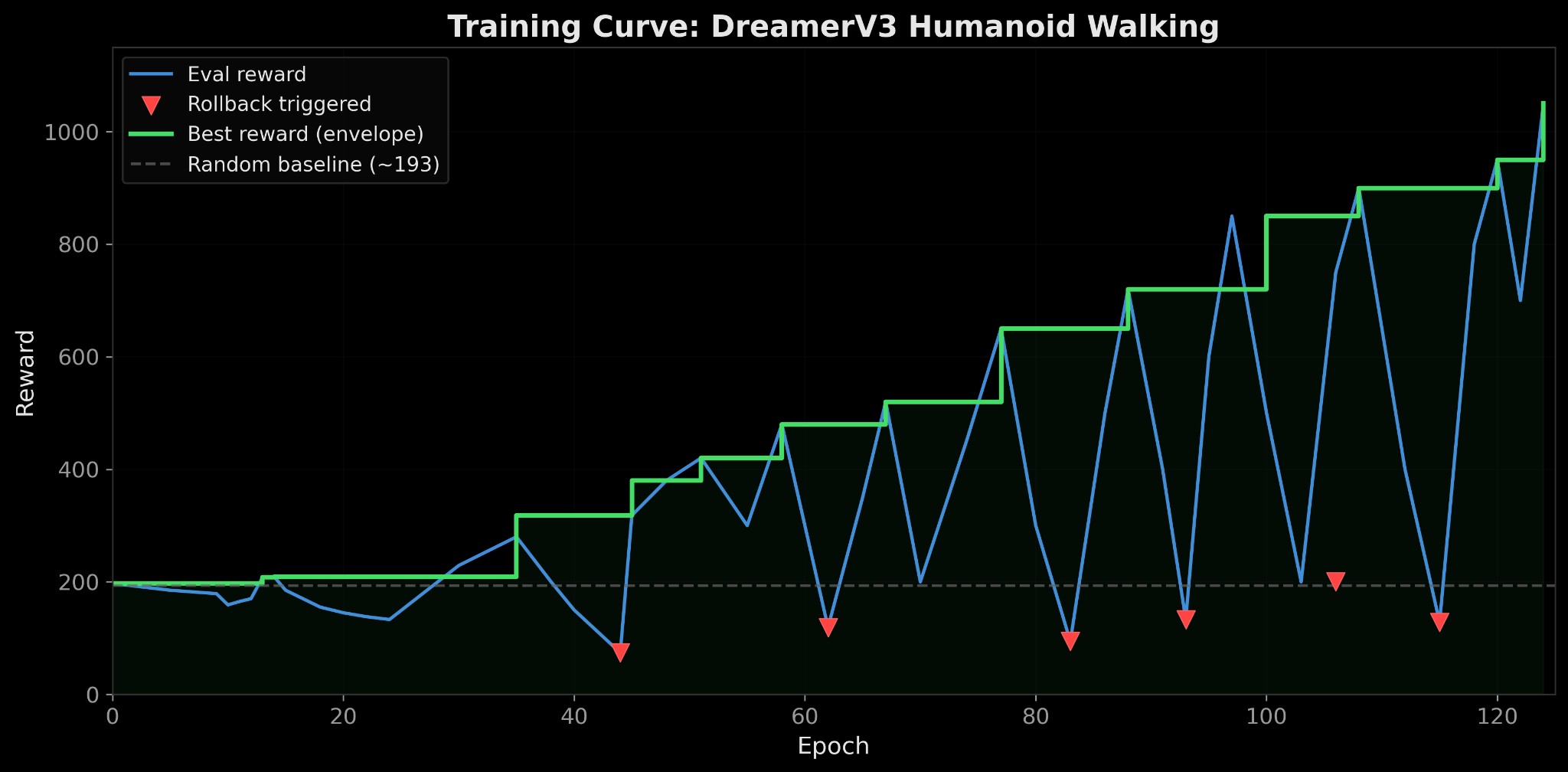
The gait itself is not graceful, it's more controlled stumble than human walk. But the variance is important since this is a stochastic policy running on a learned simulator approximating 376 dimensions of rigid body dynamics. The fact that it walks at all with a neural network learning enough about contact forces, joint limits, and momentum to generate forward locomotion through pure imagination is impressive!
All the code can be found on GitHub. Feel free to reach out at pavi.dhiman@uwaterloo.ca.
last updated 5/1/2026